

If you work in tech or are even remotely tech-curious, you’ve probably tried to understand how chatGPT works. What’s going on under the hood that allows for this kind of sorcery, and why are we experiencing it only now? How do text-to-image models really work? How do the latest text-to-video models do such a great job of modeling the physics of the real world?
AI has been a buzzword since forever, why is everyone obsessing over it now? I’ve spent a considerable amount of time thinking and researching the answers to some of these questions and recently decided to document my learnings.
This article is about understanding how foundational models like GPT work. In particular, I try to explain the intuition (and history) of the model architectures that underpin such models. With that context, let’s dive in!
Neural Networks
Before we get to GPT, it’s important first to understand how neural networks work. You can think of neural networks as algorithms that enable a machine to recognize patterns and accordingly ‘predict’ outcomes. It’s very similar to how your brain ‘predicts’ that your friend will be late for your party tonight because he was late the previous 20 times. By definition, each ‘prediction’ is a probabilistic guess, which can often deviate from the ground truth, just as how your friend could surprise you by coming early to the party!
Perhaps the most simplistic example of a neural network is a linear regression – a simple way to predict variable Y, given an input variable X and some prior data on how X maps to Y. As an example, consider predicting the price of a house (output variable Y), using its square footage (input variable X), given a prior set of 10,000 house prices calculated based on square footage (training data).
By analyzing the training data, the model understands the relationship between price and area, and over time ‘learns’ to predict the price of a new house just by receiving its area. This simple prediction model is known as a perceptron and is the most fundamental unit of a neural network.
You can see how easy it is to dial up the complexity of a simple perceptron: going back to our house example, we could include variables like zip code, number of bedrooms, wealth of neighborhood, and square footage as inputs into the model, which in turn ‘compute’ a different set of variables like quality of school, pedestrian friendliness, size of family that can be accommodated, which ultimately compute the price of the house.
In other words, each layer of the variable ‘informs’ the next layer of a slightly abstracted variable (based on complex math which we won’t get into just yet), which in turn informs the next layer (based on some more complex math) and so on, until we reach the final output layer. The more the number of intermediate layers, the more nuanced the end output.
Now imagine a network with thousands of inputs and 100s of intermediary layers, which ultimately work in sequence to compute an end output; this is known as a multi-layer perceptron – which is just technical speak for a huge, sophisticated prediction model. You can stitch together multiple multi-layer perceptrons in interesting ways, creating a highly nuanced neural network.
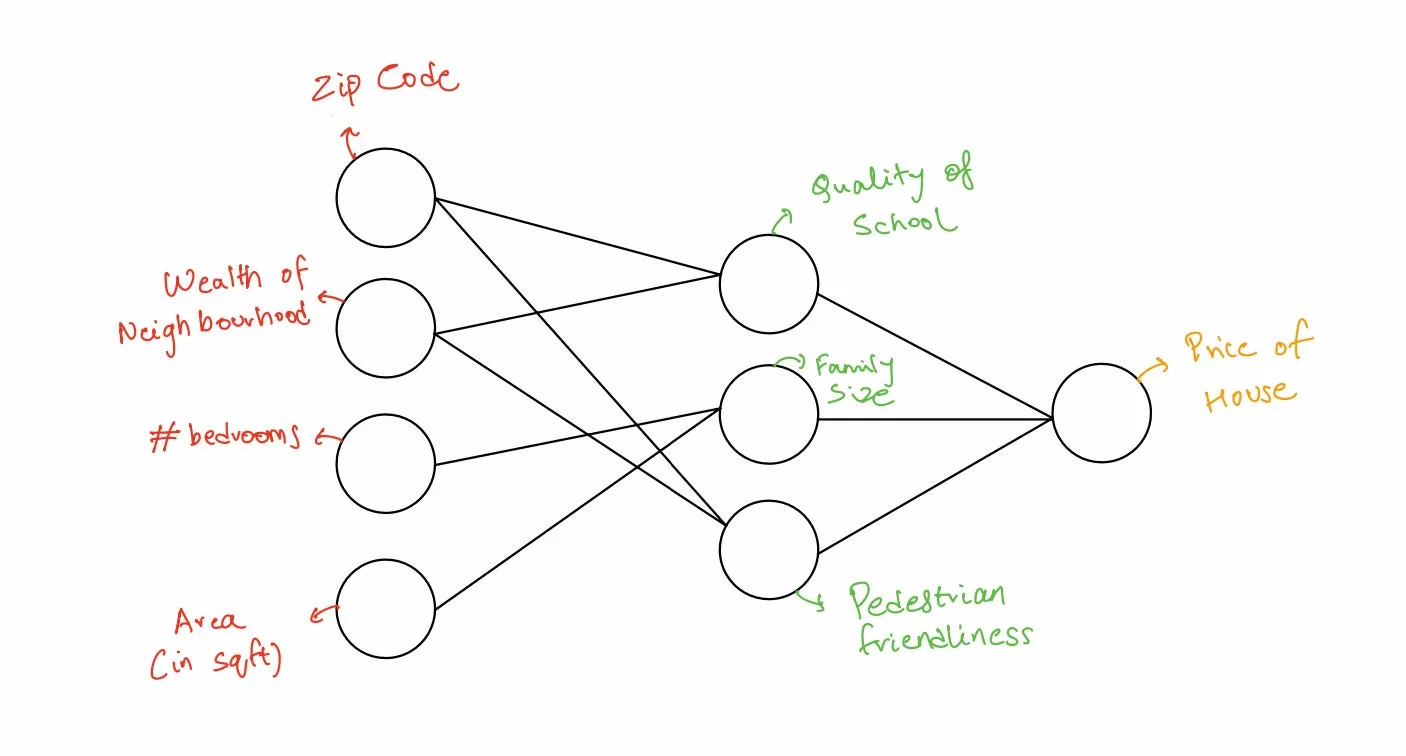
Neural networks are incredibly powerful and allow for a wide variety of ‘predictions’. In our house example, while the prediction being made was price i.e. a numerical value, we could also use a different set of neural networks to predict words, sentiments, shapes within images, etc.
While we’ve understood the power of neural networks for many decades, the manner in which we created, stitched together, and trained these networks remained specific to certain use cases and hence each field of AI – like natural language processing, image recognition, language translation, developed its own vocabulary and inevitably became distinct disciplines in and of themselves.
This was the state of things until 2017, which was when a few smart engineers from Google came together to create a new architecture of neural networks that (unbeknownst to them at the time), became the underpinning of all fields within AI. A unifying architecture of neural networks that was computationally efficient and surprisingly generalizable across domains.
In order to further our understanding of how this new architecture works, we first need to zoom into one field of AI known as sequence-to-sequence modeling.
Recurrent Neural Networks (or RNNs)
The earlier example of house price prediction is a fairly straightforward and static model – the number of inputs is pre-fixed, processed all at once and the output is usually just a single value. However, what if we want to model a ‘sequence’ of input data that has a specific order to it?
As an example, consider the task of converting an incoming stream of audio into text in real-time? Or classifying the sentiment of an ongoing Twitter thread? Or predicting the next word given a sequence of words? For each of these tasks, the order in which the data is processed matters, and each chunk of the data needs to understand the ‘context’ of all the preceding chunks.
Specific neural networks, namely recurrent neural networks or RNNs, were designed to capture this temporal dependency across a sequence of input data.
RNNs do this by capturing the context of each chunk in a sequence in a separate ‘hidden state’, which is updated with the context of each additional chunk, as we move through the sequence. This sounds complicated but allow me to explain using an example.
The auto-complete suggestion you see on your keyboard while typing a WhatsApp message uses a version of an RNN behind the scenes. The ‘context’ of the words “hello”, “how” and “are” are parsed through the RNN sequentially in order to predict the word “your”.
Subsequently, the context of “your” and all the preceding words will be used to predict the next word, and so on. Note: the innovation of RNNs was the ability to capture sequentially dependent context, however, the actual prediction of the next word is done using a version of an already well-understood multi-layer perceptron, as explained in the previous section.
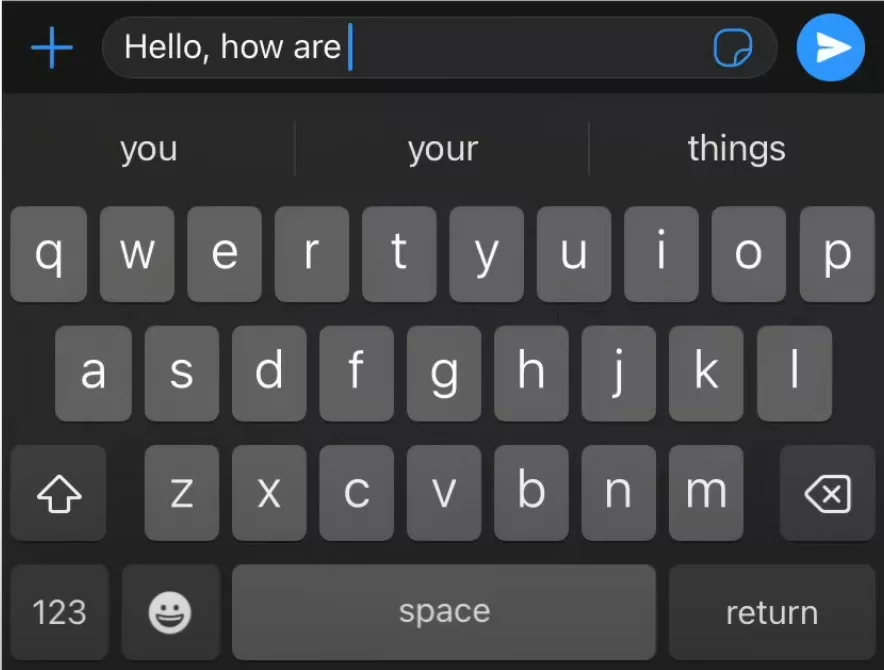
Pretty neat, right? Not quite! RNNs have their limitations. Most notably they struggle with long-range dependencies. A sentence like “I was born and raised in France, but moved to New York 5 years ago and now live with my parents & 3-year-old dog named Bruno. I speak fluent _”, will be difficult to complete given the context of being born in France (which is crucial to predict the last word), is at the very beginning of an extremely long sentence. Since RNN’s process each chunk of the word sequentially, they come with the limitation of ‘contextual loss’ by the time they reach the end of very long sequences.
An instantiation of the above limitation is highlighted in the image below – if you keep accepting the keyboard suggestion next time you’re typing a WhatsApp message, you will very quickly realize that the sentence in aggregate does not make sense, even if certain parts of it do!

Beyond this contextual loss problem, RNNs can also be computationally slow and expensive, making them most useful for short sequence modeling like the above example or simple applications like Google Translate.
Despite the limitations, RNNs captured the sequential modeling zeitgeist all through the early 2000s and 2010s. There were new flavors of it like LSTM that were adopted but the broader principle around context preservation remained the same.
Transformer
2017 was a watershed moment, principally because of the release of ‘Attention Is All You Need’ – a paper that delineated a new architecture for performing sequential modeling called the Transformer, which ended up trumping RNNs in many ways.
The Transformer architecture was a departure from RNNs in the following way: instead of parsing context from one part of the sequence to another (the boring, old RNN way), Transformers were able to identify only the most relevant parts of a sentence, and subsequently use the specific context of the most relevant parts to inform the next word prediction.
How does this work? Transformers use a technique known as ‘self-attention’ to understand the relationship of each word in a sentence with all other words and assign each relationship a relevance score.
Think of relationships as contextual dependencies in a sentence e.g. in “I was extremely hungry so I ordered a pizza”, the words “pizza” and “hungry” will likely have a deeper relationship than “I” and “pizza”. The deeper the relationship, the higher the relevance score or ‘attention similarity’. The relationships with the highest scores are subsequently used as ‘contextual weights’ in the neural network, to eventually output the most probable next word.
The outputted word is then appended to the original inputted sentence and the cycle repeats itself (a process known as autoregression) until the model detects an end-of-sequence token.
In other words, we use attention similarity to emphasize the next word prediction in a manner that is most relevant to the given sentence. Going back to our earlier example in the RNN section, the words “speak” & “France” will likely have a very high attention similarity, as will “fluent” & “speak”. These similarity scores will help in informing the model on where to focus, which will be crucial to predict the next word as “French”.
The model also uses self-attention to identify the right context of words that could have multiple meanings in isolation. For example, “money bank” & “river bank” mean two very different things and hence knowing which “bank” to focus on becomes crucial to predict what word comes next.
If you take away just one thing from this article, it should be this: the key innovation of Transformers was not that it allowed for a probabilistic prediction of the next word – this was a solved problem by RNNs and neural networks more broadly.
The key innovation was figuring out which parts of the sentence to focus on via a mechanism known as self-attention, which ultimately informed an already well-understood prediction process.
Transformers were also created in a way that allowed for parallel processing of data, making them much more computationally efficient than their legacy RNN ancestors. This was a crucial architectural design as it allowed models like GPT to be trained on all publicly available internet data, which was a crucial step to creating an application as versatile as ChatGPT.
The Transformer architecture has proven to be dramatically resilient. It was conceptualized in 2017 and is powering all modern AI applications that you and I are using today. More importantly, it has unified the vocabulary of the erstwhile distinct categories within AI and is the same architecture that is now being used in text-video and image generation, among many other use cases.
Summary
Let’s summarize! Neural networks are the building blocks of machine learning and allow us to program machines to make predictions, based on certain training data.
Sequential modeling is one such class of predictions that processes sequences of data that have temporal dependencies across different parts of the sequence (like next-word prediction in a sentence).
Up until 2017, RNNs were the predominant way of modeling sequences, however, they had their shortcomings, the biggest one being contextual loss for extremely large sequences. Transformers overcame this by enabling the model to identify contextual dependencies across all parts of a sequence and zoom in on only those parts that are most relevant to predict the next word.
Transformers also proved to be computationally very efficient and generalizable across domains. Today, they are the core building block of foundational models like GPT & DALL-E.
While the Transformer has proven to be surprisingly resilient, there is ongoing research to create newer and better architectures. Most notably, an architecture named Mamba claims to plug some of the gaps of the Transformer architecture & seems to be gaining a lot of popularity. This could potentially further improve how foundational models work.
This article was originally published on Big Ideas, Simplified.

























